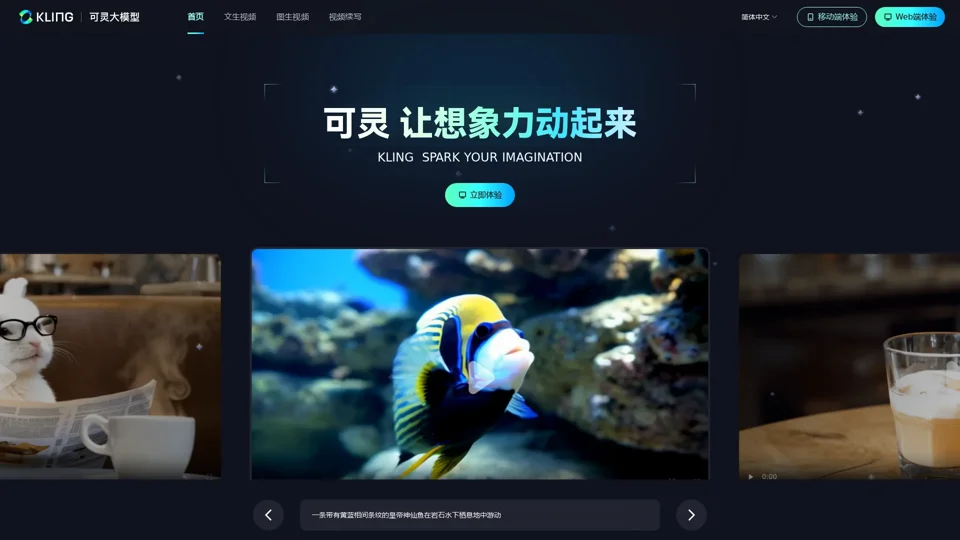
什么是可灵大模型?
可灵大模型(Kling)是由快手大模型团队自研打造的视频生成大模型,具备强大的视频生成能力,让用户可以轻松高效地完成艺术视频创作。
可灵大模型的特点
- 采用3D时空联合注意力机制,能够更好地建模复杂时空运动,生成较大幅度运动的视频内容,同时能够符合运动规律。
- 得益于高效的训练基础设施、极致的推理优化和可扩展的基础架构,可灵大模型能够生成长达2分钟的视频,且帧率达到30fps。
- 基于自研模型架构及Scaling Law激发出的强大建模能力,可灵能够模拟真实世界的物理特性,生成符合物理规律的视频。
- 基于对文本-视频语义的深刻理解和Diffusion Transformer架构的强大能力,可灵能够将用户丰富的想象力转化为具体的画面,虚构真实世界中不会出现的的场景。
- 基于自研3D VAE,可灵能够生成1080p分辨率的电影级视频,无论是浩瀚壮阔的宏大场景,还是细腻入微的特写镜头,都能够生动呈现。
- 采用了可变分辨率的训练策略,在推理过程中可以做到同样的内容输出多种多样的视频宽高比,满足更丰富场景中的视频素材使用需求。
如何使用可灵大模型?
- 可灵大模型支持对已经生成的视频进行一键续写,单次让视频运动延续4.5秒,运动内容合理、幅度显著。
- 得益于续写中的文本控制,每一段续写都能够体现用户的创意和想法。
- 支持连续多次的续写,最长可生成3分钟的视频,为创作者实现故事梦想提供了强有力的支持。
可灵大模型的应用场景
- 艺术视频创作
- 视频续写
- 视频生成
- 视频编辑
可灵大模型的优势
- 强大的视频生成能力
- 高效的训练基础设施
- 极致的推理优化
- 可扩展的基础架构
- 支持多种多样的视频宽高比
可灵大模型的未来发展
- 不断改进和优化模型的性能和功能
- 开发更多的应用场景和用例
- 提供更好的用户体验和支持